
Server maintenance Exalogic Virtual Datacenter (part 1)
Published on: Author: Jos Nijhoff Category: OracleThis post explores the options Exalogic Virtual Datacenter (vDC) administrators have when maintenance has to be performed on one or more Exalogic compute nodes (physical servers in an Exalogic serverpool). This can be hardware maintenance (e.g. replace a defective memorycard) or software maintenance (e.g. a quarterly Patch Set Update with latest bug- and/or security fixes).

Of course, when performing such maintenance, you want to minimize the impact on your hosted middleware and application environments. For this, maintenance mode for compute nodes would be just what the doctor ordered…
Maintenance mode for Exalogic compute nodes
Officially, maintenance mode is not (yet) supported on Exalogic, or so I thought. However, a few weeks ago, I chanced upon MOS Note 1551724.1, titled “Making an OVS Node Unavailable for vServer Placement in Exalogic Virtual Environments using EMOC.” This note is a good step in the right direction, as it describes how you can prevent new virtual machines to be allocated on a particular compute node or nodes by “tagging” them as unavailable. What’s more, it also details how to move your vServers around in the pool.
A good case for testing the new procedure
Now al we needed was a good testing opportunity. As it happens, our X2-2 was up for preventive maintenance as the RAID HBA batteries for the SSD’s in all the eight compute nodes needed to be replaced by an Oracle Engineer. For this, every compute node had to be briefly shutdown, a module replaced and then restarted, taking about 10 minutes in all per node. An excellent opportunity to test the new procedure.
Exalogic vServer lifecycle
Before we go into the details, I need to explain some of the basics of vServer operation within the Exalogic vDC, i.e. the vServer lifecycle. When a vServer is provisioned from an available template and type, a new virtual machine is created in the Oracle VM serverpool. As we have a quarter rack, we have just one serverpool consisting of eight nodes. In a full rack, you would have four server pools, two pools of eight nodes and two pools of 7.

Exalogic Control employs a placement algorithm to determine on which physical node to best allocate the new vServer, taking into account such factors as vServer size, resource utilization at each node and the allocation of other vServers in the distribution group, if applicable. Thus, the vServer is usually assigned to a node that has the most free resources in terms of CPU and memory, and is the least ‘busy’ of them. However, if another vServer in the same distribution group is already running there, another node will be chosen.
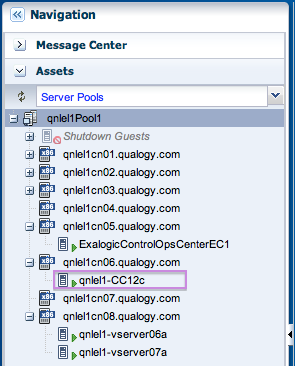
When we stop the vServer, the virtual machine is halted and then deallocated from the compute node it was running on, and returned to the ‘Shutdown Guests’ category, which corresponds to the ‘Unassigned Virtual Machines’ folder at the Oracle VM level, as illustrated below.

When the vServer is restarted, the placement algorithm comes into play again, and the vServer may now be placed on a different node as resource availability and utilization accross the eight nodes may have changed since last startup. In the example below, I have started our Cloud Control 12c vServer ‘qnlel1-CC12c’ and it was allocated to node 6 by Exalogic Control, which was not hosting any vServers yet.
In short, this is how the vServer lifecycle works, but there’s one more thing you need to know.
Since the release of version 2.0.4.0.0 (Navstar) in december 2012, vServers can be put into High Availability mode. This (somewhat misleading) term means that when in ‘vServer HA’ mode, vServers will automatically be restarted when terminated abnormally, either because the virtual machine itself or the physical node it is running on fails. It does not involve ‘live migration’. In Ops Center screens, it is also called ‘automatic recovery’ which is a better monniker. A separate blogpost on my testing with vServer High Availability will be posted soon. Now it’s time to go back to the subject at hand, maintenance mode.
How does tagging a compute node for maintenance work?
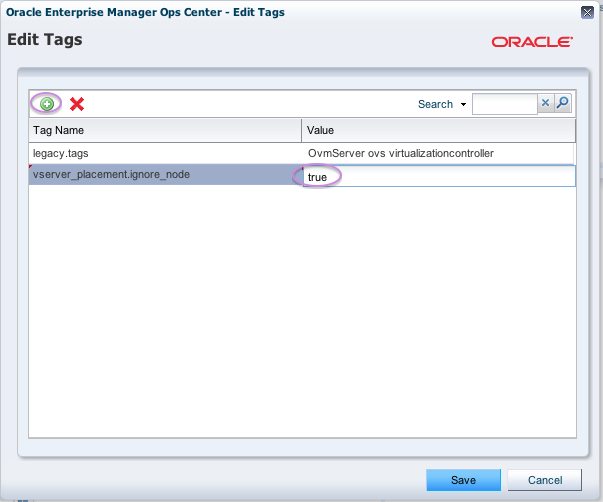
According to MOS Note 1551724.1, there are two ways to tag a particular node to indicate it will go into maintenance. The first way is to is to set the tag vserver_placement.ignore_node=true for the node. This will stop new vServers to be allocated to this node upon normal startup or creation. However, it will not stop ‘emergency reallocation’ of a vServer when using vServer High Availability mode. A vServer that fails (a rare event, but still) might incidently be restarted on our tagged node.
The most interesting part of the MOS note comes after this: effectively, in step 3 a method for offline vServer migration is provided by stopping and then restarting all vServers on the tagged node! Now that’s a useful perk indeed.
The second way to tag a compute node is to actually place it into maintenance mode. This will also prevent vServers in HA mode to be restarted on said compute node.
Testing maintenance mode in a real life scenario
Now back to our maintenance testing opportunity, the preventive replacement of the RAID HA batteries for the SSD’s in our eight compute nodes. We decided to perform this action in four groups of two nodes. Thus we could prevent downtime for high available (HA) configurations (i.e. clustered applications and middleware having at least 2 nodes that can take over from each other) and to minimize downtime for non-HA configurations.
We have a HA OSB cluster, a Traffic Director cluster and and 3rd party Java application running on Weblogic to test with and as a non-HA ready environment we have PeopleSoft Campus and Cloud Control proof of concept environments hosted on our Exalogic, a Fusion Apps and a Traffic Director admin vServer.

For the HA-ready (i.e. clustered) environments, we just have to make sure we will not take down any nodes hosting more than one vServer of the same WebLogic Cluster at the same time (so vServers that are in the same distribution group). Below we can see some HA-ready environments (OSB, OTD, UTS). For our test, primary nodes of each HA configuration are running on node 6 and secondary nodes on node8.
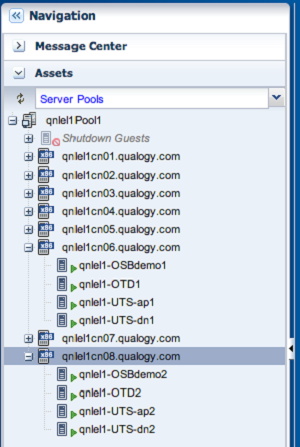
Taking compute nodes 7 and 8 out of service
We now start to take nodes 7 and 8 out of service. In prepartion, we tag them with vserver_placement.ignore_node=true and put them into maintenance mode, as shown below for node 7 :

Double check on the Summary tab if our tagging action on node 7 succeeded :
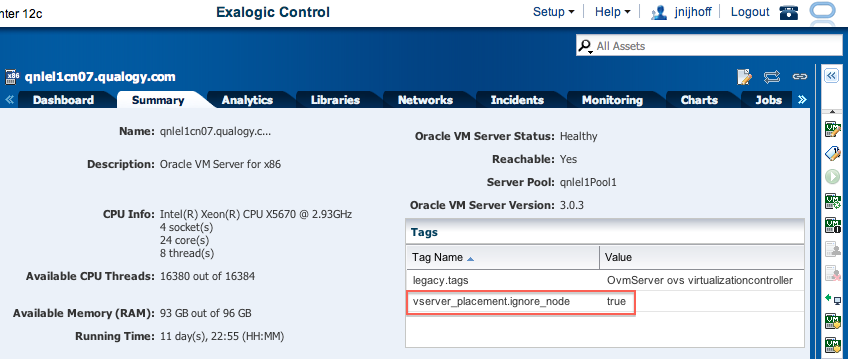
With this action, no new vServers will be allocated on node 7 until we ‘untag’ it. Next, place node 7 into maintenance mode as well, so no automatic recovery can incidently override the policy and recover a vServer on this node.
Quoting from MOS Note 1551724.1:
Note: If an HA-enabled vServer fails, while selecting a node for restarting the failed vServer, Exalogic Control considers all of the available nodes, including those that are tagged with vserver_placement.ignore_node=true.
I found that you do not actually need to stop all vServers on the node before entering maintenance mode, this can be done afterwards as well, which seems more locgical. However this is not what the offical procedure advises.

Unfortunately, as yet the icons in Exalogic Control do not reflect the status change for node 7 and 8, so we cannot see directly that these nodes have gone into maintenance. That seems like a good enhancement request for the product.
In the underlying OVM Manager however, this can be seen quite well:

Note the little gears on the icons for nodes 7 and 8.
Now we are ready to stop and restart all vServers on nodes 7 and 8 to relocate them and subsequently halt these compute nodes so they can be serviced. This will be examined in part 2 of this Exalogic maintenance story.


